
One of the consequences of cheap storage is that we have no incentive to reduce the amount of data we keep. We believe that we’re going to be able to search for whatever we want. But we are starting to exceed our human capacity to filter the returned results of our searches. Algorithms will help us some, but they are never going to be enough as long as we keep adding data at this rate. We’re going to have to use metadata to help us find anything.
Taxonomy
For centuries, we have organized data taxonomically. All living creatures have a place in the Linnean structure. I am a chordate, a mammal, a primate, a human. There are lots of library organization systems that organize books and information. For example, the Library of Congress system has categories for everything, and room left for categories of knowledge we haven’t found yet.
Taxonomy has several problems, though. For one thing, you can only sort something into one bin at a time. Constraining things into only one category means you may not think to look in the correct places and assume that the information doesn’t exist.
Taxonomy also replicates the power structures of the culture that makes the organizational, which can be problematic. For example, there was a time when the Library of Congress system categorized Native Americans as fauna of North America. It’s always going to be dangerous to underrepresented groups to encode knowledge as the domain of a dominant group. And even if it’s not dangerous, it’s othering and discouraging.
Folksonomy
The solution that has been arising lately is called folksonomy. Folksonomy is assigning tags to a piece of knowledge, based on the contributions of many individuals. You’re already using folksonomy in more places than you know. For example, Amazon recommendations uses both taxonomy and folksonomy to drive recommendations, and so does Netflix. We use it as individuals many times we are trying to describe something that we don’t know the exact name of.
The value of folksonomy is that it doesn’t depend on a top-down organizational system. Instead, it builds an understanding and description of something from many different perspectives. Like the parable of the six blind men and the elephant, the elephant may seem very different to you based on your perspective. For example, records of the Salem Witch Trials might be about early American history, or about Puritans, or about the suppression of women’s expression, or about the racism involved. The records don’t change, but their category and description does, according to who you are, what your perspective is, and what you are seeking to teach or understand.
The downside of folksonomy is that humans are sometimes terrible, and if you leave any system of public contribution completely open, people will attempt to spoil it or use their voice to dominate it. Imagine if every instance of a book that contained Christianity or a reference to communion got deluged with hundreds of tags about cannibalism. It would become difficult to find anything that was actually about cannibalism, and most people looking for documents about Christianity would find their results pushed farther down.
The other problem with folksonomy is one of standardization. If people can freely enter tags, they will enter very slight variants. Not intentionally, but it’s just extremely hard for anyone to be perfectly consistent, let alone many people. If tags vary, then they are not useful for grouping things together, because “King Arthur” and “Arthur, King of the Britons” will not be returned together, even though he is the same historical person. Conversely, “Shaun” might return you an adorable claymation sheep or a zombie-fighting slacker. You’d need to disambiguate them to get clear results.
Tag-Wrangling and Transformative Works
The organization that I have seen balance these conflicting values best is called Archive of Our Own. AO3 is a non-profit organization devoted to hosting transformational works. Transformational works are anything that takes a source text and tells a new story, or alters the text to convey a new point of view. Because US copyright law is not yet very clear about transformational works, this is also united with an academic journal and a lobbying movement to promote the idea of transformational works as a legitimate artistic expression.
Warning: Although nothing in this post is explicit, the AO3 site hosts many sexually explicit works. I do not recommend visiting the site on a monitored system or if you choose to avoid sexually explicit material.
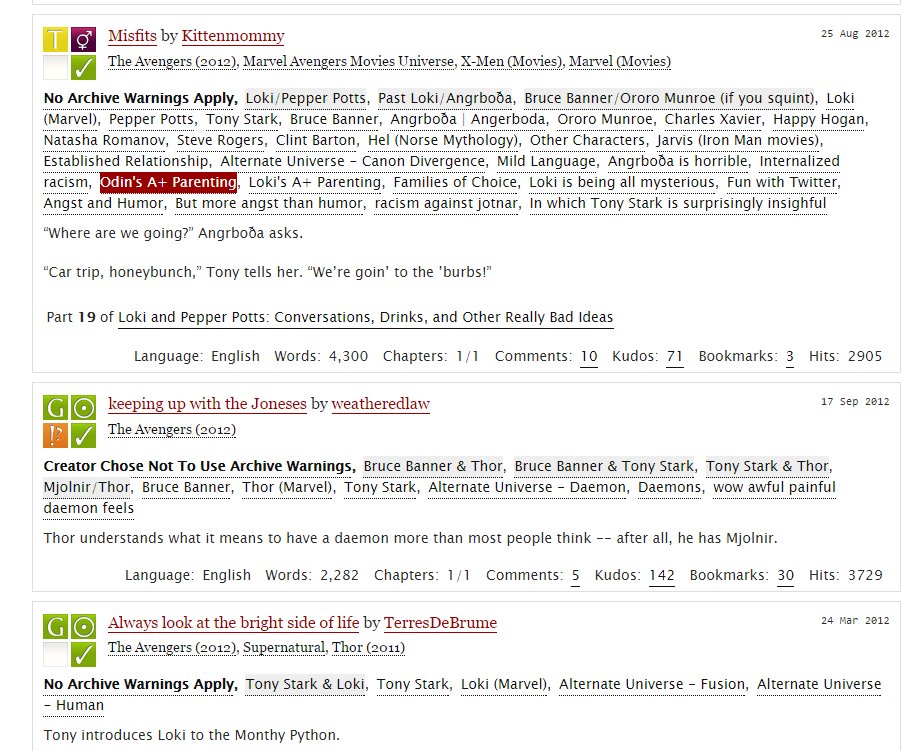
AO3 uses a combination of taxonomy and folksonomy to make hundreds of thousands of fanfic stories available to people who are looking for them. Users can search by story title or author, or they can step through to increasingly fine categories, such as Movies->Marvel->Captain America->Winter Soldier. Stories are then further sorted on pairings, if there is a romantic element.

Authors can give stories tags. These tags frequently convey authorial commentary, or appeal to a specific in-group of readers. They also function in a descriptive role. For example, a story might be tagged:
- Odin’s A+ Parenting
- Thor/Hulk
- Thor/Banner
- Loki (Marvel)
- Thor (Marvel)
- Hulk (Marvel)
- LGBTQ Character
- Humor
- Drama
- Curtain fic
- Longfic
These tags are a mix of authorial description and comment (Odin’s A+ Parenting, Curtain fic), and “canonical tags”, which are standardized tags which describe specific characters or media sources (Loki (Marvel)). If you just searched on “Loki”, you would get both the Marvel version and the mythology version. “Python” returns both Monty Python and snakes.
Tagging also includes warnings about types of content that people find distressing. Being able to select tags away means that people will never be accidentally exposed to something they work to avoid. The community has agreed on a general set of things that will either be explicitly warned for or the whole story will be assigned “Author Chose Not To Use Warning Tags”, which means there could be anything in there, take your own risks.

The canonical tags are managed by a small army of volunteers known as “tag wranglers”. These amazing humans standardize common tags and character and source tags, and also group together similar tags. For example, if you click on the tag/link “Odin’s A+ Parenting”, you’ll see a Tag Page:
The tag wranglers have collated similar and related tags and grouped them together so that reader’s searches have more chance of success. For example, I’m American, so when I am sarcastically assigning an excellent grade, I say “A+”. But British fic-readers might instead say, “Odin’s A-level parenting”. They mean the same thing, but you would have to have an EXTREMELY well-trained machine learning system to link that, or you would need humans. Tag wranglers also work to maintain and standardize warning tags.
The Art of Indexing
One of the early influences on me as a technical writer, before I knew technical writing was a thing, was reading Kurt Vonnegut’s Cat’s Cradle. Mostly, it’s a story of apocalyptic greed, but there’s a throwaway passage:
It appeared that Clair Minton, in her time, had been a professional indexer. I had never heard of such a profession before. She told me that she had put her husband through college years before with her earnings as an indexer, that the earnings had been good, and that few people could index well.
The idea of that passage stuck with me, the thought that indexing is an art worth paying for. When I became a technical writer, I was pretty junior, and ended up with the boring assignment of generating indexes. FrameMaker made this easy enough by parsing out headings to create index entries, and I even had a tool that would permute the headings for me, so I would get entries for Shaving the Cat and Cat, Shaving. But I was unsatisfied with that result, because it was just about the headings, and sometimes I was missing key concepts, so I had to go through and do manual indexing anyway.
So often, when we say indexing now, what we mean is a concordance, not an index. A concordance is a straightforward listing of all the places a word or phrase appears in a document. An index is more carefully constructed, and only points to useful instances of a phrase or word, like introductions or significant mentions. A really good index will also include words that never appear in a document.
User language is not our language
For example, if I show you this picture

you probably identify it as the Blue Screen of Death. But until about 5 years ago, you would not find that phrase if you searched the Microsoft website. If you had the problem, you would need to search on “fatal exception”. It’s deeply unsatisfying to look for help and not find it. Even now, you won’t find a Microsoft help page about it on the first page of Google results.
If we want to serve our users, we need to meet them where they are, using the language that they use. So if they call something a spinning beach ball or a blue screen of death or whatever, use it in addition to the name that you call it.
The point of indexing something is to make your product and documentation easier for people to use. If you are not using the language that they use, you’re only writing the documentation and index for people who already work for you.
You won’t be able to imagine the names that people call your product (hopefully good). You’ll find their words in the places that they are helping each other. Stack Overflow, user groups, mailing lists, the files and reports that your own support team keeps.
Once you’ve collected all the language that people are using, you need to roll it into your index. You don’t want to identify every instance of a phrase, only the ones that actually pertain to the answers people are looking for. You want people to get the answer, not a deluge of partially relevant information.
Attach the index tags to the place with the best solutions, and also the meta tags that you want to include in the index. For example, if you have a heading called Activating your Thromdimbulator, you will want the following index tags associated with it:
- Activate thromdimulator
- Turn on thromdimbulator
- Activate thingy
- Turn on thingy
That’s the human indexing effect. There is an index entry that has zero words in common with the heading but will still be exactly what someone needs if they think of their thromdimbulator as a “thingy” that they want to “turn on”.
Human indexing is hard, because it takes time and knowledge and deep product and industry knowledge. But the reward is that even in our search-oriented, automatically-generated world, an excellent index is going to set your product apart.
This post is an expansion on a lightning talk I gave at PyConAU 2016 and Confoo Montreal 2017.